Syncing Markdown Notes to NotebookLM Using Google Apps Script
After discovering NotebookLM last December, I began importing my notes to make them easier to search and review. While NotebookLM's RAG capabilities are powerful and it offers many useful features, maintaining existing content can be quite inconvenient.
The biggest issue is the duplicate upload handling mechanism. Even if you upload a file with the same name, NotebookLM treats it as a brand-new source, resulting in both the old and new versions coexisting. For someone like me who constantly iterates on notes, having to delete the old source before uploading the new one every time is a huge hassle. Currently, there doesn't seem to be an official API for batch management, so I cannot automate this process via API.
Of course, if you don't care about the conversation history within the notes, you could delete the entire notebook, create a new one, and re-upload everything. However, since I migrated my notes from HackMD to GitHub Pages and started organizing them into folders, the level of difficulty has increased. I cannot select all notes at once; I have to click into subfolders layer by layer to select articles, all while manually excluding unnecessary files.
NotebookLM's Sync Mechanism and Pain Points
NotebookLM currently supports syncing specific formats from Google Drive, such as Google Docs, Google Slides, PDFs, and Word (.docx) files. When a cloud file is updated, NotebookLM displays a sync prompt:
The downside is that you must click into individual sources to perform the sync; there is no way to batch process them from the list page, but I have to make do with it for now.
How can I leverage NotebookLM's Drive sync mechanism to solve my problem? First, let's review the current bottlenecks:
- File Filtering: Although I can specify a local folder to sync with Google Drive, my notes are part of a VitePress site, which includes many non-note files (such as configuration files, images, etc.).
- Format Support: My notes are all Markdown (
.md) files, but NotebookLM's Google Drive sync feature does not support reading.mdfiles directly. - Directory Structure Dilemma: Notes are organized in folders, requiring batch selection and upload, which is tedious.
To solve these problems, I needed a "relay service." After discussing it with Gemini, it suggested Google Apps Script (GAS).
The solution logic is as follows:

Google Apps Script Implementation
1. Create a Project
Go to script.google.com and click "New Project." You will see the following interface:
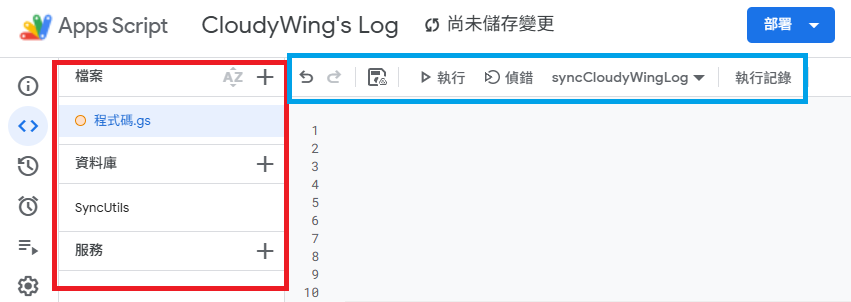
A brief explanation of the interface sections (as shown above):
- Red Box Area:
- Files: Manage
.gs(code) and.htmlfiles. - Libraries: Used to reference external libraries.
- Services: Used to connect to advanced Google APIs; not needed for this project.
- Files: Manage
- Blue Box Area: The standard code editor. In the image,
syncCloudyWingLogis the function list where you can select and execute functions.
Google Apps Script is essentially JavaScript. Just paste the code from the two blocks below and make the following adjustments to use it.
2. Configure Project Parameters
Paste the following code into Code.gs. You need to modify these variables:
TargetFolderId: The ID of the target folder where converted Google Docs will be stored (can be obtained from the folder's URL).SourceFolderId: The ID of the source Markdown folder.- Since Google Drive Desktop syncs to the "Computer" section, you cannot get the ID directly from the URL like a standard Drive folder. You can use the
findCorrectFolderId()helper function below; changetargetFolderNameto your sync folder name, run it, and get the correct ID from the logs.
- Since Google Drive Desktop syncs to the "Computer" section, you cannot get the ID directly from the URL like a standard Drive folder. You can use the
- If you place these two code blocks in the same project, change
SyncUtils.startSyncEngine(...)tostartSyncEngine(...).
Only syncCloudyWingLog() is an execution function; the other two are temporary utilities.
function syncCloudyWingLog() {
const sourceFolderId = 'Source Folder Id';
const targetFolderId = 'Target Folder Id';
// Set file whitelist (only sync .md)
const whitelistFiles = [
/\.md$/i
];
// Set file blacklist
const blacklistFiles = [
/^index\.md$/i,
/^about\.md$/i,
/^tags\.md$/i
];
const whitelistFolders = [];
const blacklistFolders = [];
// If calling directly in the same project, remove SyncUtils.
SyncUtils.startSyncEngine(
sourceFolderId,
targetFolderId,
whitelistFiles,
blacklistFiles,
whitelistFolders,
blacklistFolders
);
}
// Helper function: Find the ID of a folder synced by Google Drive Desktop
function findCorrectFolderId() {
const targetFolderName = 'docs';
const folders = DriveApp.getFoldersByName(targetFolderName);
Logger.log('Searching for folder named "' + targetFolderName + '"...');
let found = false;
while (folders.hasNext()) {
const folder = folders.next();
found = true;
// Get parent folder name to determine location
const parents = folder.getParents();
let parentName = 'None (possibly root or special area)';
if (parents.hasNext()) {
parentName = parents.next().getName();
}
Logger.log('------------------------------------------------');
Logger.log('📁 Folder Name: ' + folder.getName());
Logger.log('🆔 ID (Please copy this): ' + folder.getId());
Logger.log('🏠 Located in (Parent): ' + parentName);
Logger.log('🔗 URL: ' + folder.getUrl());
}
if (!found) {
Logger.log('❌ Could not find any folder named "' + targetFolderName + '". Please check if the name case is correct.');
}
}
// Helper function: Clean up ghost files generated during testing
function killGhostFile() {
var ghostId = '1Fd6GQzsZBvgmSeV23AP1PxKSQnL10aXDeRY98btPb60';
try {
var file = DriveApp.getFileById(ghostId);
console.log('👻 Caught it! Ghost file name: ' + file.getName());
console.log('📂 Location: ' + (file.getParents().hasNext() ? file.getParents().next().getName() : "None (Orphaned file)"));
console.log('🗑️ In Trash: ' + file.isTrashed());
file.setTrashed(true);
console.log('✅ Successfully moved ghost file to trash!');
} catch (e) {
console.log('❌ ID not found, it might have already disappeared. Error: ' + e.message);
}
}TIP
When you run any function in the project for the first time (e.g., findCorrectFolderId or syncCloudyWingLog), Google will pop up an "Authorization Required" window.
This is because the script needs to scan your Google Drive folders, read Markdown file content, and create Google Docs. Click "Review Permissions" and select your Google account. If you see a "Google hasn't verified this app" warning, click "Advanced" and then "Go to... (unsafe)" to complete the authorization. This is a script you wrote yourself, so please feel free to use it.
3. Core Sync Logic
This part handles recursive folder scanning, Markdown reading, and the creation/updating of Google Docs.
/**
* Start the sync engine
* @param {string} sourceId - Source folder ID
* @param {string} targetId - Target folder ID
* @param {Array<RegExp>} fileWhite - File whitelist
* @param {Array<RegExp>} fileBlack - File blacklist
* @param {Array<RegExp>} folderWhite - Folder whitelist
* @param {Array<RegExp>} folderBlack - Folder blacklist
*/
function startSyncEngine(sourceId, targetId, fileWhite, fileBlack, folderWhite, folderBlack) {
const sourceFolder = DriveApp.getFolderById(sourceId);
const targetFolder = DriveApp.getFolderById(targetId);
console.log('🚀 Starting sync... (Mode: Markdown -> Google Doc + Chunked Writing)');
processFolderFlattened(sourceFolder, targetFolder, "", fileWhite, fileBlack, folderWhite, folderBlack);
}
/**
* Recursively process folders and flatten the structure
* @param {Folder} currentSource
* @param {Folder} rootTarget
* @param {string} prefix
* @param {Array<RegExp>} fileWhite
* @param {Array<RegExp>} fileBlack
* @param {Array<RegExp>} folderWhite
* @param {Array<RegExp>} folderBlack
*/
function processFolderFlattened(currentSource, rootTarget, prefix, fileWhite, fileBlack, folderWhite, folderBlack) {
const files = currentSource.getFiles();
while (files.hasNext()) {
const file = files.next();
const originalName = file.getName();
if (isAllowed(originalName, fileWhite, fileBlack)) {
let baseName = (prefix ? prefix + "_" : "") + originalName;
const targetDocName = baseName.replace(/\.md$/i, "");
try {
syncFileToGoogleDoc(file, rootTarget, targetDocName);
} catch (e) {
console.error("❌ Failed to process file [" + targetDocName + "]: " + e.toString());
}
// Prevent API Rate Limiting
Utilities.sleep(150);
}
}
const subFolders = currentSource.getFolders();
while (subFolders.hasNext()) {
const subFolder = subFolders.next();
const subName = subFolder.getName();
if (isAllowed(subName, folderWhite, folderBlack)) {
const nextPrefix = (prefix ? prefix + "_" : "") + subName;
processFolderFlattened(subFolder, rootTarget, nextPrefix, fileWhite, fileBlack, folderWhite, folderBlack);
}
}
}
/**
* Sync a single file to Google Doc (with retry mechanism)
* @param {File} sourceFile
* @param {Folder} targetFolder
* @param {string} targetDocName
*/
function syncFileToGoogleDoc(sourceFile, targetFolder, targetDocName) {
const maxRetries = 3;
let attempt = 0;
let success = false;
while (attempt < maxRetries && !success) {
try {
attempt++;
const existingFiles = targetFolder.getFilesByName(targetDocName);
let targetDocFile = null;
while (existingFiles.hasNext()) {
const f = existingFiles.next();
if (f.getMimeType() === MimeType.GOOGLE_DOCS) {
targetDocFile = f;
break;
}
}
if (targetDocFile) {
if (sourceFile.getLastUpdated() > targetDocFile.getLastUpdated()) {
console.log(' 🔄 [Update] ' + targetDocName + (attempt > 1 ? ` (Retry ${attempt})` : ""));
updateDocContent(targetDocFile.getId(), sourceFile);
}
} else {
console.log(' ➕ [New] ' + targetDocName + (attempt > 1 ? ` (Retry ${attempt})` : ""));
createDocContent(targetFolder, targetDocName, sourceFile);
}
success = true;
} catch (e) {
if (attempt < maxRetries) {
console.warn(`⚠️ Failed, retrying (${attempt}/${maxRetries}): ${targetDocName}`);
Utilities.sleep(attempt * 3000);
} else {
throw new Error(`Failed after ${maxRetries} retries: ` + e.message);
}
}
}
}
/**
* Write long text content in chunks (Chunking Strategy)
* @param {Body} docBody
* @param {string} fullText
*/
function writeContentInChunks(docBody, fullText) {
const CHUNK_SIZE = 20000;
// Initialization: Clear and create an initial empty paragraph
docBody.setText("");
if (!fullText || fullText.length === 0) {
return;
}
for (let i = 0; i < fullText.length; i += CHUNK_SIZE) {
const chunk = fullText.substring(i, i + CHUNK_SIZE);
// Must get the current last paragraph object to perform appendText
const paragraphs = docBody.getParagraphs();
const lastParagraph = paragraphs[paragraphs.length - 1];
if (lastParagraph) {
lastParagraph.appendText(chunk);
} else {
docBody.appendParagraph(chunk);
}
Utilities.sleep(150);
}
}
/**
* Update existing Google Doc content
* @param {string} docId
* @param {File} sourceFile
*/
function updateDocContent(docId, sourceFile) {
const content = sourceFile.getBlob().getDataAsString();
const doc = DocumentApp.openById(docId);
const body = doc.getBody();
// Must keep File ID unchanged, update content in place to ensure NotebookLM references and conversation history remain intact
writeContentInChunks(body, content);
doc.saveAndClose();
}
/**
* Create a new Google Doc and write content
* @param {Folder} targetFolder
* @param {string} docName
* @param {File} sourceFile
*/
function createDocContent(targetFolder, docName, sourceFile) {
const content = sourceFile.getBlob().getDataAsString();
const doc = DocumentApp.create(docName);
const body = doc.getBody();
writeContentInChunks(body, content);
doc.saveAndClose();
const docFile = DriveApp.getFileById(doc.getId());
docFile.moveTo(targetFolder);
}
/**
* Check if name matches whitelist/blacklist rules
* @param {string} name
* @param {Array<RegExp>} whitelist
* @param {Array<RegExp>} blacklist
* @returns {boolean}
*/
function isAllowed(name, whitelist, blacklist) {
if (blacklist && blacklist.some(pattern => pattern.test(name))) return false;
if (!whitelist || whitelist.length === 0) return true;
return whitelist.some(pattern => pattern.test(name));
}4. Deploy the Project
If you have multiple sets of notes to sync, as a slightly experienced engineer, you wouldn't copy-paste all the code into every project. Here, I maintain the "Core Sync Logic (SyncUtils)" as an independent project, and other projects call it via references. Later, you only need to adjust the whitelist/blacklist for each project and call startSyncEngine().
- In the core logic project, click "Deploy" -> "New deployment" in the top right.
- Select "Library" as the type.
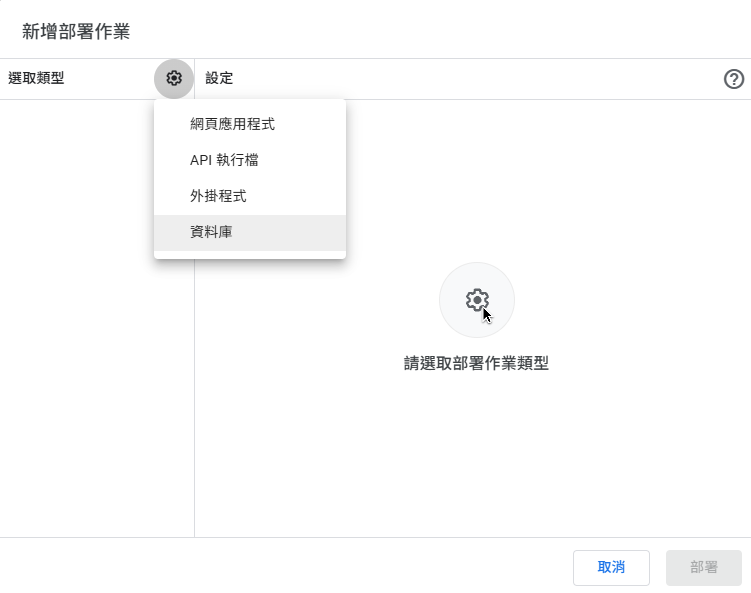
- Enter a description and click "Deploy." A screen will appear with a "Deployment ID," but that is for websites and we don't need it.
- We need the "Script ID" shown below. Copy it and return to your original project.
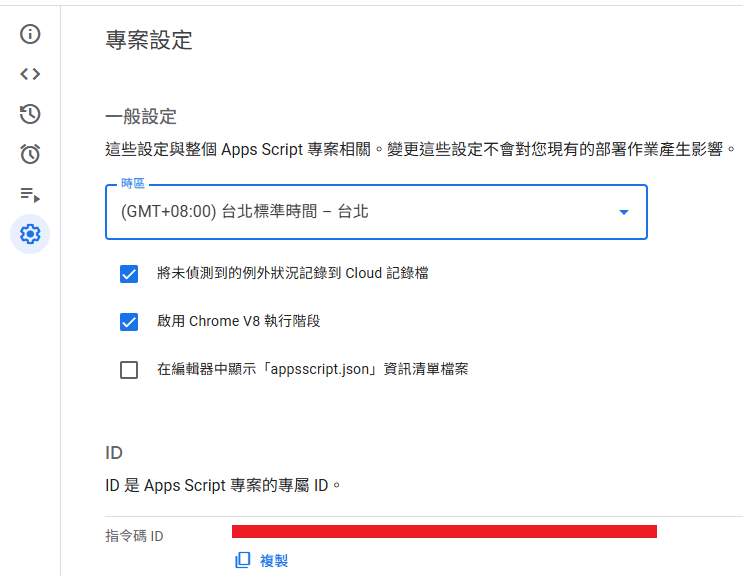
- Click the
+next to "Libraries" on the left and paste the ID you just copied.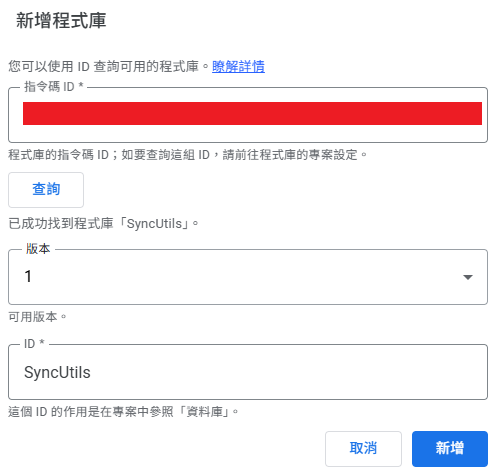
Configuration Tips:
- Version: The dropdown shows "1" and "Head" (latest code snapshot).
- Using Git concepts, every time we save the library project, a commit is generated. "Head" points to the latest commit. Deployments create version tags, so "Version 1" corresponds to the first tag.
- "Head" is suitable for the development phase: when the library project is still being adjusted and you don't want to redeploy a version every time you test, the referencing project can choose this version. Once functionality is confirmed, you can officially publish a version.
- Identifier: This is the variable name used when calling this library in your code.
- Importance: The
SyncUtilsinSyncUtils.startSyncEngine(...)corresponds to this setting. If you change it here, the code must be updated, or it won't find the object. - Decoupling Benefits: The ID defaults to the library project name, but they are decoupled. This means even if you rename the remote library project to
SyncUtils_v2_Backupin the future, as long as you keep the Identifier set toSyncUtilshere, the original code requires no changes and will continue to work.
- Importance: The
5. Set Automation Triggers
Finally, set up an automated schedule so the sync runs in the background.
Click the alarm clock icon (Triggers) on the left:
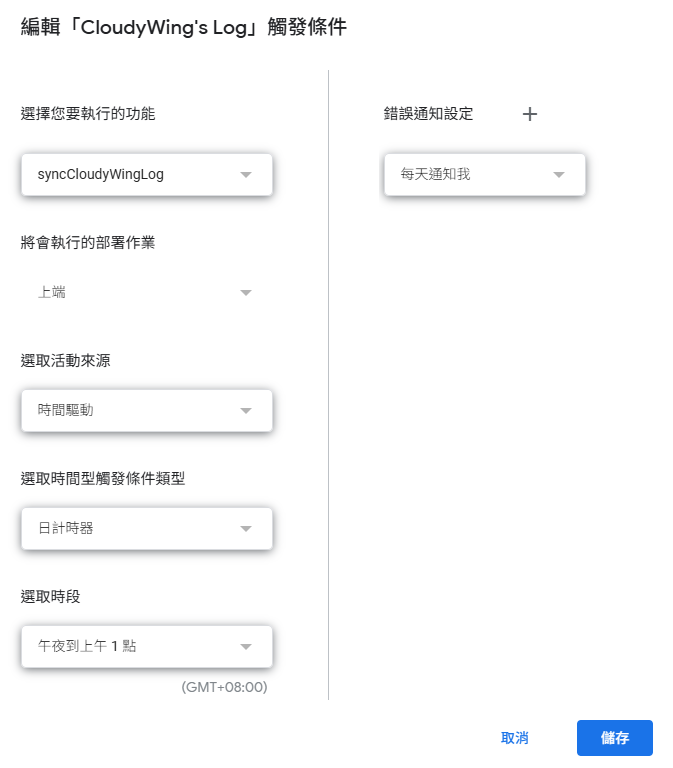
Add a trigger, select syncCloudyWingLog (or your main function), set the event source to "Time-driven," and set the frequency as needed (e.g., hourly).
Honestly, this workflow is just "barely usable," but it's the best I can think of at this stage. For the rest, I can only hope Google eventually improves the NotebookLM file management interface.
Other Failed Attempts
The main article ends here. The following is just a record of some attempts made during the technical selection process.
Before deciding to return to NotebookLM, I tried setting up a local AI knowledge base, but it wasn't as simple as I imagined.
AI Server Selection
LM Studio
- Pros: Very friendly UI, suitable for beginners or those just wanting to experience models. You can search and download models from HuggingFace directly in the interface.
- Reason for giving up: Likely due to the more polished UI or being built on Electron, it consumes more resources. Plus, I couldn't find a setting for it to start automatically on boot, so I decided to give it up.
TIP
We usually go to HuggingFace to download models. Besides official releases, there are many versions adjusted based on official models. These adjustments might be Abliterated (removing refusal mechanisms), Uncensored, or fine-tuned for specific purposes.
- Uncensored: Usually trained without alignment data, which might produce inappropriate responses.
- Abliterated: A common term in the open-source community, referring to modifying model weights (e.g., removing vectors responsible for refusing requests) to "forget" refusal mechanisms, allowing it to answer sensitive questions. This is generally recommended for jailbreaking.
Ollama
- Pros: Low resource consumption, supports auto-start and automatic VRAM allocation, suitable for advanced users who need long-term operation or API integration.
- Cons: Relies on CLI commands, which is less friendly to users not accustomed to the terminal. However, most servers only require operation during setup, so it's mostly just running in the background.
TIP
I previously had a misconception about Ollama, thinking it could only download models from the Ollama platform. If I wanted to use other models, I had to download the GGUF file and import it using a ModelFile. Actually, around October 16, 2024, support for HuggingFace downloads was provided (it's been supported for a long time!). For details, refer to You can now run directly with Ollama and Use Ollama with any GGUF Model on Hugging Face Hub.
KoboldCpp
- Pros: Single executable (portable), no installation required; excellent Context Shifting handling (suitable for long text/context switching).
- Cons: Requires manual parameter adjustment, slightly higher learning curve.
I chose it later because I needed stronger context capabilities for other requirements.
Knowledge Platforms
Open Web UI
I set it up with Docker and deleted it after playing for half an hour. It's very powerful, but I feel it's more suitable for corporate knowledge platforms where you can manage accounts and groups, which I don't need.
AnythingLLM
Supports multi-account mode and single-user use, supports AI Agents. In terms of functionality, it fits my needs better.
However, while using it, I realized my understanding of their operating mechanism was wrong. I originally thought I could just select my note folder as the data path to search, but that's not how it works. It requires an "import" action to build a Vector Index for the notes, which leads to the following problems:
- Slow Import: Default import takes time. I eventually switched to the
bge-m3model to resolve this. - Parameter Sensitivity: There are two parameters,
Chunk SizeandChunk Overlap, which affect how it processes imported data. Finding the best settings takes time, and every time you change them, the notes must be re-imported. What happens if the settings aren't tuned well? A simple comparison: I have two notes, "Common Package Management - Visual Studio" and "Common Package Management - Visual Studio Code." In NotebookLM, if I ask it to search for Visual Studio common packages, it gives me the correct list. In AnythingLLM, even if I explicitly say I want Visual Studio packages but not Visual Studio Code, it still returns Visual Studio Code content, often incomplete or mixed with other irrelevant notes.
TIP
When importing notes into a vector database, the system cannot process the entire article at once and must split it into small chunks.
- Chunk Size: The size of each block. Too large might include irrelevant information (noise); too small might break the semantics.
- Chunk Overlap: The overlapping part between blocks. Ensures that context near the split point is preserved, preventing sentences from being cut in the middle.
These two need to be tuned based on the average length and type of notes (code or general text) to achieve the best search results.
Besides the "finding data" settings being troublesome, the "answering questions" brain is also important.
Even if the data is found correctly, if the backend AI model is incapable, the quality of the answer will be greatly reduced.
For example, I find Gemini Flash's answers often frustrating. Models with reasoning capabilities (like Gemini Flash Thinking) are much better. So, I once tried DeepSeek-R1-Distill-Qwen-14B as a local model, and I saw that when searching notes, it had to spend time on Chain of Thought before answering. I suddenly realized that Flash still has its place and is more suitable for this occasion than Reasoning Models.
Also, if you want to customize the Prompt but don't explicitly instruct the model to refer to the provided context, the model might ignore the data spliced in the background and answer using its own training knowledge.
However, this doesn't mean Open Web UI and AnythingLLM aren't good. It's just that the former has excessive features for me; the latter, since my notes have no privacy concerns, would cost too much time to tune or research plugins to meet my needs. Plus, if I want to mount different models for different services, my VRAM isn't enough. Weighing the options, I'd rather spend my time on other AI tools, so I ultimately chose to return to NotebookLM.
Author's Postscript: A Tragedy of Unsaved Files
Since I previously used Antigravity, it could read files even if I hadn't saved them, so I didn't pay much attention to saving.
This time, after finishing the draft, I asked Antigravity to help proofread and update the file title. I saw a new tab appear and closed the old file's tab. The tragedy happened. Antigravity read the unsaved content (about 1/3 of the full text) and "optimized" it based on that incomplete content, leading to illogical output. When I asked it to restore the original saved version, it said it couldn't.
In the end, I could only recover that 1/3 from the history and had to rewrite the remaining 2/3, which took about 3 hours.
This was mainly my operational negligence; I can only say my usage habits were too careless, and I didn't even do basic backup precautions.
It's 3:30 AM as I write this. The keyboard suddenly failed, and after restarting, the internet disconnected... Looks like heaven is urging me to sleep, orz.
Changelog
- Initial document created.